
操作场景
腾讯云第六代实例 S6 和第五代实例 S5、M5、C4、IT5、D3 全面采用第二代智能英特尔®至强®可扩展处理器 Cascade Lake。提供了更多的指令集和特性,可用于加速人工智能的应用,同时集成的大量硬件增强技术,其中 AVX-512(高级矢量扩展)能够为 AI 推理过程提供强劲的并行计算能力,使用户获得更好的深度学习效果。本文以 S5、M5 实例为例,介绍如何在 CVM 上通过 AVX512 加速人工智能应用。
选型推荐
云服务器的多种实例规格可用于多种应用开发,其中 标准型 S6、标准型 S5 及 内存型 M5 适用于机器学习或深度学习。这些实例配备了第二代 Intel®Xeon®处理器,适配 Intel® DL boost 学习能力。推荐配置如下表:
| 平台类型 | 实例规格 |
| 深度学习训练平台 | 84vCPU 的标准型 S5 实例或 48vCPU 的内存型 M5 实例。 |
| 深度学习推理平台 | 8/16/24/32/48vCPU 的标准型 S5 实例或内存型 M5 实例。 |
| 机器学习训练或推理平台 | 48vCPU 的标准型 S5 实例或 24vCPU 的内存型 M5 实例。 |
具备优势
使用 Intel®Xeon® 可扩展处理器运行机器学习或深度学习工作负载时,具备以下优势:适合处理大内存型工作负载、医学成像、GAN、地震分析、基因测序等场景中使用的 3D-CNN 拓扑。支持使用简单的 numactl 命令进行灵活的核心控制,也适用小批量的实时推理。强大的生态系统支持,可直接在大型集群上进行分布式训练,避免额外添加大容量存储和昂贵的缓存机制来进行规模化架构的训练。可在同一个集群中支持多种工作负载(例如 HPC、BigData、AI 等),获取更优的 TCO。通过 SIMD 加速,满足众多实际深度学习应用程序的计算要求。同一套基础架构可直接用于训练及推理。
操作步骤
创建实例
创建云服务器实例,详情请参见 通过购买页创建实例。其中,实例规格需根据 选型推荐 及实际业务场景进行选择。如下图所示:
 说明更多实例规格参数介绍,请参见 实例规格。
说明更多实例规格参数介绍,请参见 实例规格。
登录实例
登录云服务器实例,详情请参见 使用标准方式登录 Linux 实例(推荐)。
部署示例
您可根据实际业务场景,参考以下示例部署人工智能平台,进行机器学习或深度学习任务:示例1:使用 Intel®优化深度学习框架 TensorFlow*在第二代智能英特尔®至强®可扩展处理器 Cascade Lake 上 PyTorch 和 IPEX 会自动启用针对 AVX-512 指令集进行的优化,以尽可能提高运算性能。TensorFlow* 是用于大规模机器学习及深度学习的热门框架之一。您可参考该示例,提升实例的训练及推理性能。更多框架部署相关信息,请参见 Intel® Optimization for TensorFlow* Installation Guide。操作步骤如下:
部署 TensorFlow* 框架
1. 在云服务器中,安装 Python。本文以 Python 3.7 为例。2. 执行以下命令,安装 Intel® 优化的 TensorFlow* 版本 intel-tensorflow。说明建议使用2.4.0及以上版本,以获得最新的功能与优化。
pip install intel-tensorflow
设置运行时优化参数
选择运行时参数优化方式。通常会使用以下两种运行接口,从而采取不同的优化设置。您可结合实际需求选择,更多参数优化配置说明请参见 General Best Practices for Intel® Optimization for TensorFlow。Batch inference:设置 BatchSize >1,并测量每秒可以处理的输入张量总数。通常情况下,Batch Inference 方式可以通过使用同一个 CPU socket 上的所有物理核心来实现最佳性能。On-line Inference(也称为实时推断):设置 BS = 1,并测量处理单个输入张量(即一批大小为1)所需时间的度量。在实时推理方案中,可以通过多实例并发运行来获取最佳的吞吐。操作步骤如下:1. 执行以下命令,获取系统的物理核个数。
lscpu | grep "Core(s) per socket" | cut -d':' -f2 | xargs
2. 设置优化参数,可选择以下任一方式:设置环境运行参数。在环境变量文件中,添加以下配置:
export OMP_NUM_THREADS= # export KMP_AFFINITY="granularity=fine,verbose,compact,1,0" export KMP_BLOCKTIME=1 export KMP_SETTINGS=1 export TF_NUM_INTRAOP_THREADS= # export TF_NUM_INTEROP_THREADS=1 export TF_ENABLE_MKL_NATIVE_FORMAT=0
在代码中增加环境变量设置。在运行的 Python 代码中,加入以下环境变量配置:
import osos.environ["KMP_BLOCKTIME"] = "1"os.environ["KMP_SETTINGS"] = "1"os.environ["KMP_AFFINITY"]= "granularity=fine,verbose,compact,1,0"if FLAGS.num_intra_threads > 0: os.environ["OMP_NUM_THREADS"]= # os.environ["TF_ENABLE_MKL_NATIVE_FORMAT"] = "0"config = tf.ConfigProto()config.intra_op_parallelism_threads = # config.inter_op_parallelism_threads = 1tf.Session(config=config)
运行 TensorFlow* 深度学习模型的推理
可参考 Image Recognition with ResNet50, ResNet101 and InceptionV3 运行其他机器学习/深度学习模型推理。本文以 benchmark 为例,介绍如何运行 ResNet50 的 inference benchmark。详情请参见 ResNet50 (v1.5)。
运行 TensorFlow* 深度学习模型的训练
本文介绍如何运行 ResNet50 的 training benchmark,详情请参见 FP32 Training Instructions。
TensorFlow 性能展示
性能数据可参见 Improving TensorFlow* Inference Performance on Intel® Xeon® Processors,根据实际模式、物理配置的不同,性能数据会有一定差别。以下性能数据仅供参考:延时性能:
通过测试,在 batch size 为1时选取适用于图像分类、目标检测的一些模型进行测试,会发现使用 AVX512 优化的版本相对于非优化版本所提供的推理性能有一些明显提升。例如在延迟上,优化后的 ResNet 50的延时降低为原来的45%。吞吐量性能:
通过设置增加 batch size 来测试吞吐性能,选取适用于图像分类、目标检测的一些模型进行测试,发现在吞吐的性能数据上也有明显提升,优化后 ResNet 50的性能提升为原来的1.98倍。示例2:部署深度学习框架 PyTorch*
部署步骤
1. 在云服务器中,安装 Python3.6 或以上版本,本文以 Python 3.7 为例。2. 前往 Intel® Extension for PyTorch 官方github repo,根据安装指南中提供的信息,对 PyTorch 以及 Intel® Extension for PyTorch (IPEX) 进行编译以及安装。
设置运行时优化参数
在第二代智能英特尔®至强®可扩展处理器 Cascade Lake 上 PyTorch 和 IPEX 会自动启用针对 AVX-512 指令集进行的优化,以尽可能提高运算性能。您可按照本步骤设置运行时参数优化方式,更多参数优化配置说明请参见 Maximize Performance of Intel® Software Optimization for PyTorch* on CPU。Batch inference:设置 BatchSize > 1,并测量每秒可以处理的输入张量总数。通常情况下,Batch Inference 方式可以通过使用同一个 CPU socket 上的所有物理核心来实现最佳性能。On-line Inference(也称为实时推断):设置 BatchSize = 1,并测量处理单个输入张量(即一批大小为1)所需时间的度量。在实时推理方案中,可以通过多实例并发运行来获取最佳的吞吐量。操作步骤如下:1. 执行以下命令,获取系统的物理核个数。
lscpu | grep "Core(s) per socket" | cut -d':' -f2 | xargs
2. 设置优化参数,可选择以下任一方式:设置环境运行参数,使用 GNU OpenMP* Libraries。在环境变量文件中,添加以下配置:
export OMP_NUM_THREADS=physicalcoresexport GOMP_CPU_AFFINITY="0-"export OMP_SCHEDULE=STATICexport OMP_PROC_BIND=CLOSE
设置环境运行参数,使用 Intel OpenMP* Libraries。在环境变量文件中,添加以下配置:
export OMP_NUM_THREADS=physicalcoresexport LD_PRELOAD=export KMP_AFFINITY="granularity=fine,verbose,compact,1,0"export KMP_BLOCKTIME=1export KMP_SETTINGS=1
运行 PyTorch* 深度学习模型的推理及训练优化建议
运行模型推理时,可使用 Intel® Extension for PyTorch 来获取性能提升。示例代码如下:
import intel_pytorch_extension...net = net.to('xpu') # Move model to IPEX formatdata = data.to('xpu') # Move data to IPEX format...output = net(data) # Perform inference with IPEXoutput = output.to('cpu') # Move output back to ATen format
推理及训练都可使用 jemalloc 来进行性能优化。jemalloc 是一个通用的 malloc(3) 实现,强调避免碎片化和可扩展的并发支持,旨在为系统提供的内存分配器。jemalloc 提供了许多超出标准分配器功能的内省、内存管理和调整功能。详情请参见 jemalloc 及 示例代码。关于多 socket 的分布式训练,详情请参见 PSSP-Transformer 的分布式 CPU 训练脚本。
性能结果
基于 Intel 第二代英特尔®至强®可扩展处理器 Cascade Lake,在2*CPU(28核/CPU)及384G内存场景下,不同模型测试的性能数据可参见 性能测试数据。由于实际模型及物理配置不同,性能数据会有差别,本文提供的测试数据仅供参考。示例3:使用 Intel®AI 低精度优化工具加速Intel® 低精度优化工具是一个开源的 Python 库,旨在提供一个简单易用的、跨神经网络框架的低精度量化推理接口。用户可以通过对该接口的简单调用来对模型进行量化,提高生产力,从而加速低精度模型在第三代 Intel® Xeon® DL Boost 可扩展处理器平台上的推理性能。更多使用介绍请参见 Intel® 低精度量化工具代码仓库。
支持的神经网络框架版本
Intel® 低精度优化工具支持:
Intel® 优化的 TensorFlow* v1.15.0、v1.15.0up1、v1.15.0up2、 v2.0.0、v2.1.0、v2.2.0、v2.3.0和v2.4.0。
Intel® 优化的 PyTorch v1.5.0+cpu 和 v1.6.0+cpu。
Intel® 优化的 MXNet v1.6.0、v1.7.0以及 ONNX-Runtime v1.6.0。
实现框架
Intel® 低精度优化工具实现框架示意图如下: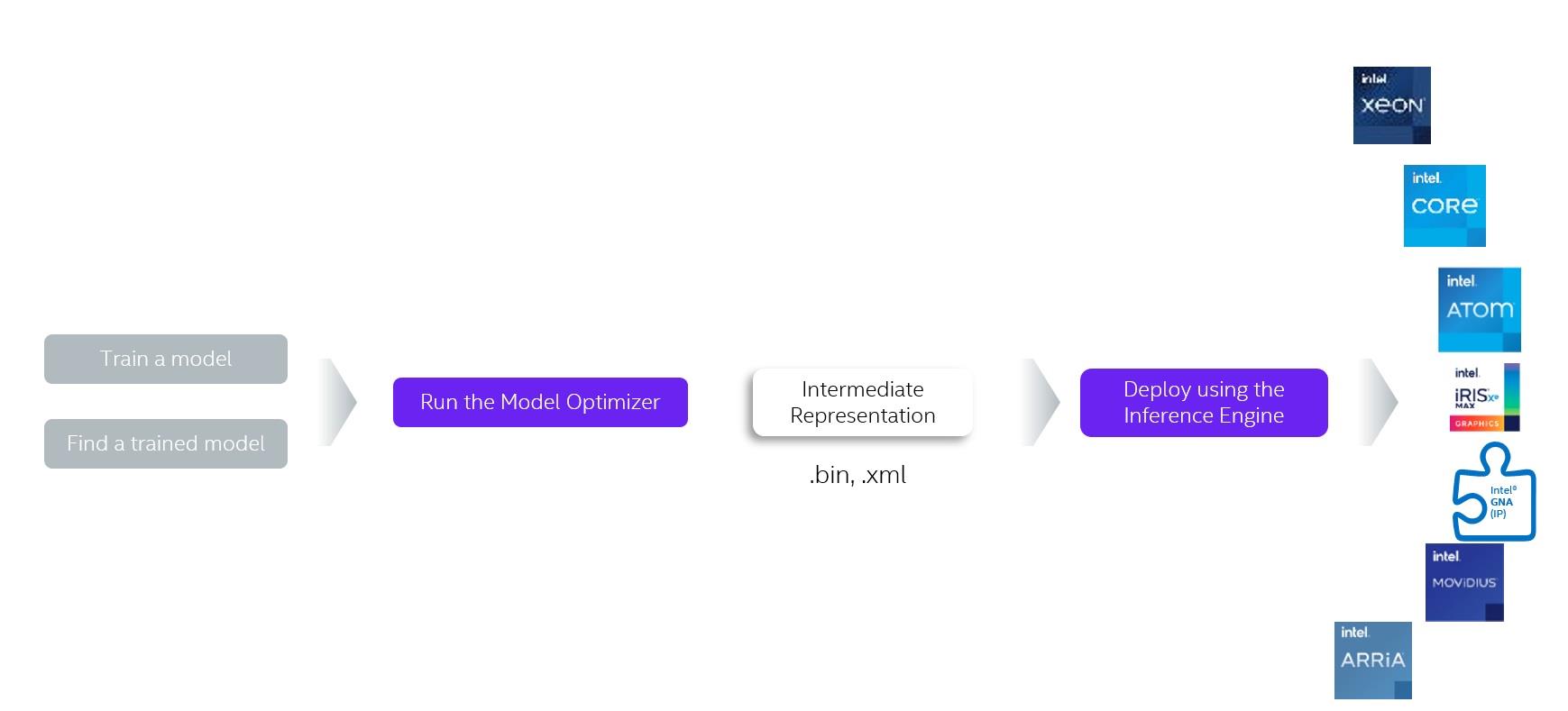
工作流程
Intel® 低精度优化工具工作流程示意图如下: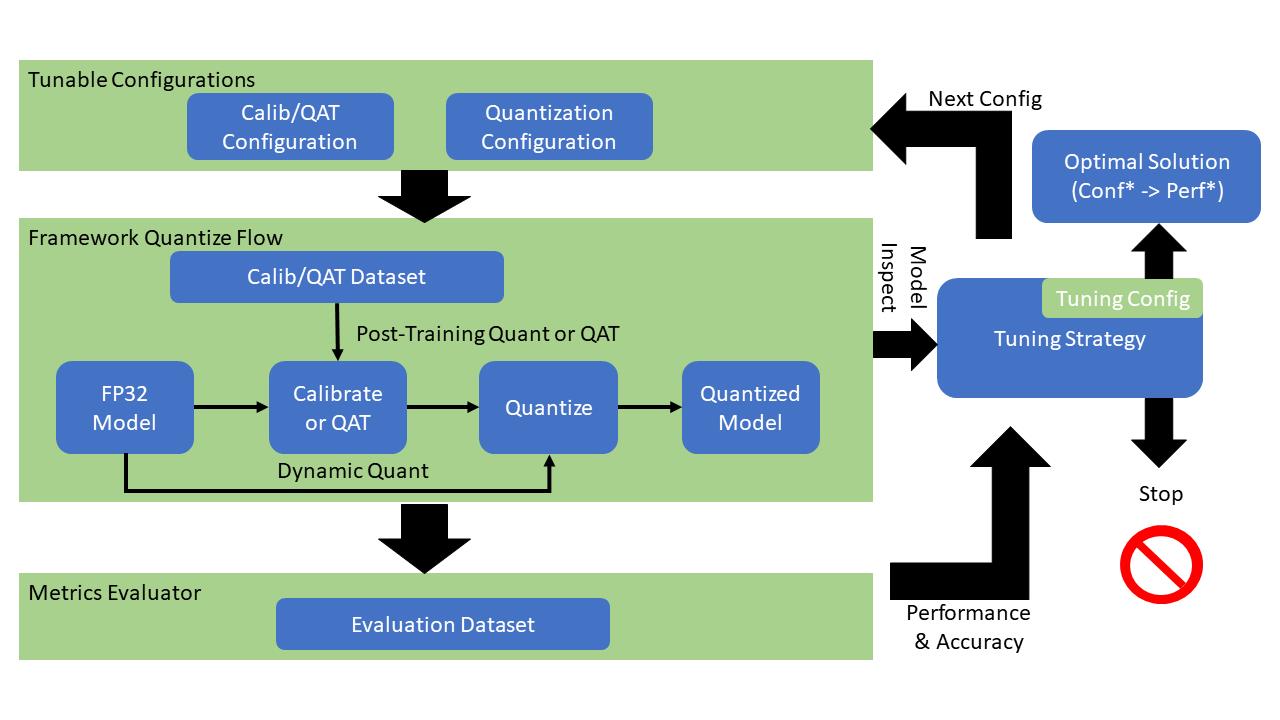
量化模型性能与精度示例
部分由 Intel® 低精度优化工具量化的模型在 Intel 第二代英特尔®至强®可扩展处理器 Cascade Lake 的获得的性能与精度如下:
| Framework | Version | Model | Accuracy | Performance speed up | ||
| | | | INT8 Tuning Accuracy | FP32 Accuracy Baseline | Acc Ratio [(INT8-FP32)/FP32] | Realtime Latency Ratio[FP32/INT8] |
| tensorflow | 2.4.0 | resnet50v1.5 | 76.92% | 76.46% | 0.60% | 3.37x |
| tensorflow | 2.4.0 | resnet101 | 77.18% | 76.45% | 0.95% | 2.53x |
| tensorflow | 2.4.0 | inception_v1 | 70.41% | 69.74% | 0.96% | 1.89x |
| tensorflow | 2.4.0 | inception_v2 | 74.36% | 73.97% | 0.53% | 1.95x |
| tensorflow | 2.4.0 | inception_v3 | 77.28% | 76.75% | 0.69% | 2.37x |
| tensorflow | 2.4.0 | inception_v4 | 80.39% | 80.27% | 0.15% | 2.60x |
| tensorflow | 2.4.0 | inception_resnet_v2 | 80.38% | 80.40% | -0.02% | 1.98x |
| tensorflow | 2.4.0 | mobilenetv1 | 73.29% | 70.96% | 3.28% | 2.93x |
| tensorflow | 2.4.0 | ssd_resnet50_v1 | 37.98% | 38.00% | -0.05% | 2.99x |
| tensorflow | 2.4.0 | mask_rcnn_inception_v2 | 28.62% | 28.73% | -0.38% | 2.96x |
| tensorflow | 2.4.0 | vgg16 | 72.11% | 70.89% | 1.72% | 3.76x |
| tensorflow | 2.4.0 | vgg19 | 72.36% | 71.01% | 1.90% | 3.85x |
| Framework | Version | Model | Accuracy | Performance speed up | ||
| | | | INT8 Tuning Accuracy | FP32 Accuracy Baseline | Acc Ratio [(INT8-FP32)/FP32] | Realtime Latency Ratio[FP32/INT8] |
| pytorch | 1.5.0+cpu | resnet50 | 75.96% | 76.13% | -0.23% | 2.46x |
| pytorch | 1.5.0+cpu | resnext101_32x8d | 79.12% | 79.31% | -0.24% | 2.63x |
| pytorch | 1.6.0a0+24aac32 | bert_base_mrpc | 88.90% | 88.73% | 0.19% | 2.10x |
| pytorch | 1.6.0a0+24aac32 | bert_base_cola | 59.06% | 58.84% | 0.37% | 2.23x |
| pytorch | 1.6.0a0+24aac32 | bert_base_sts-b | 88.40% | 89.27% | -0.97% | 2.13x |
| pytorch | 1.6.0a0+24aac32 | bert_base_sst-2 | 91.51% | 91.86% | -0.37% | 2.32x |
| pytorch | 1.6.0a0+24aac32 | bert_base_rte | 69.31% | 69.68% | -0.52% | 2.03x |
| pytorch | 1.6.0a0+24aac32 | bert_large_mrpc | 87.45% | 88.33% | -0.99% | 2.65x |
| pytorch | 1.6.0a0+24aac32 | bert_large_squad | 92.85 | 93.05 | -0.21% | 1.92x |
| pytorch | 1.6.0a0+24aac32 | bert_large_qnli | 91.20% | 91.82% | -0.68% | 2.59x |
| pytorch | 1.6.0a0+24aac32 | bert_large_rte | 71.84% | 72.56% | -0.99% | 1.34x |
| pytorch | 1.6.0a0+24aac32 | bert_large_cola | 62.74% | 62.57% | 0.27% | 2.67x |
说明表中的 PyTorch 和 Tensorflow 均指基于 Intel 优化后的框架。
Intel®低精度优化工具安装与使用示例
1. 依次执行以下命令,使用 anaconda 建立名为 lpot 的 python3.x 虚拟环境。本文以 python 3.7 为例。
conda create -n lpot python=3.7conda activate lpot
2. 安装 lpot,可通过以下两种方式:执行以下命令,从二进制文件安装。
pip install lpot
执行以下命令,从源码安装。
git clone https://github.com/intel/lpot.git cd lpot pip install –r requirements.txt python setup.py install
3. 量化 TensorFlow ResNet50 v1.0。本文以 ResNet50 v1.0 为例,介绍如何使用本工具进行量化:3.1 准备数据集。
执行以下命令,下载并解压 ImageNet validation 数据集。
mkdir –p img_raw/val && cd img_raw
wget http://www.image-net.org/challenges/LSVRC/2012/dd31405981
ef5f776aa17412e1f0c112/ILSVRC2012_img_val.tar
tar –xvf ILSVRC2012_img_val.tar -C val执行以下命令,将 image 文件移入按 label 分类的子目录。
cd val
wget -qO -https://raw.githubusercontent.com/soumith/
imagenetloader.torch/master/valprep.sh | bash执行以下命令,使用脚本 prepare_dataset.sh 将原始数据转换为 TFrecord 格式。
cd examples/tensorflow/image_recognition/tensorflow_models
bash prepare_dataset.sh --output_dir=./data --raw_dir=/PATH/TO/img_raw/val/
--subset=validation
更多数据集相关信息,请参见 Prepare Dataset。3.2 执行以下命令,准备模型。
wget https://storage.googleapis.com/intel-optimized-tensorflow/models/v1_6/resnet50_fp32_pretrained_model.pb
3.3 执行以下命令,运行 Tuning。
修改文件 examples/tensorflow/image_recognition/resnet50_v1.yaml,使 quantization\calibration、evaluation\accuracy、evaluation\performance 三部分的数据集路径指向用户本地实际路径,即数据集准备阶段生成的 TFrecord 数据所在位置。详情请参见 ResNet50 V1.0。
cd examples/tensorflow/image_recognitionbash run_tuning.sh --config=resnet50_v1.yaml \--input_model=/PATH/TO/resnet50_fp32_pretrained_model.pb \--output_model=./lpot_resnet50_v1.pb
3.4 执行以下命令,运行 Benchmark。
bash run_benchmark.sh --input_model=./lpot_resnet50_v1.pb--config=resnet50_v1.yaml``` 输出结果如下,其中性能数据仅供参考:```shellsession accuracy mode benchmarkresult: Accuracy is 0.739 Batch size = 32 Latency: 1.341 ms Throughput: 745.631 images/sec performance mode benchmark result: Accuracy is 0.000 Batch size = 32 Latency: 1.300 ms Throughput: 769.302 images/sec
示例4:使用 Intel® Distribution of OpenVINO™ Toolkit 进行推理加速Intel® Distribution of OpenVINO™ Toolkit 是一个可以加快计算机视觉及其他深度学习应用部署的工具套件,它能够支持英特尔平台的各种加速器(包括 CPU、GPU、FPGA 以及 Movidius 的 VPU)来进行深度学习,同时能直接支持异构硬件的执行。Intel® Distribution of OpenVINO™ Toolkit 能够优化通过 TensorFlow* 、PyTorch* 等训练的模型, 它包括模型优化器、推理引擎、Open Model Zoo、训练后优化工具(Post-training Optimization Tool)等一整套部署工具,其中:模型优化器(Model optimizer):将 Caffe*、TensorFlow* 、PyTorch* 和 Mxnet* 等多种框架训练的模型转换为中间表示(IR)。推理引擎(Inference Engine):将转换后的 IR 放在 CPU、GPU、FPGA 和 VPU 等硬件上执行,自动调用硬件的加速套件实现推理性能的加速。您可前往 Intel® Distribution of OpenVINO™ Toolkit 官网 或查阅 在线文档 了解更多信息。
工作流程
Intel® Distribution of OpenVINO™ Toolkit 工具套件工作流程示意图如下:
Intel® Distribution of OpenVINO™ Toolkit 推理性能
The Intel® Distribution of OpenVINO™ 工具在多种英特尔处理器与加速硬件上提供了优化实现。在英特尔®至强®可扩展处理器平台上,它使用了Intel® DL Boost 与 AVX-512 指令集进行推理网络的加速。关于各平台的性能数据,请参见 Intel® OpenVINO™ 工具套件基准性能数据。
使用 Intel® Distribution of OpenVINO™ Toolkit 深度学习开发套件(DLDT)
请参考以下资料:Intel® 深度学习部署工具包简介图像分类 C++ 示例(异步模式)对象检测 C++ 示例(SSD)自动语音识别 C++ 示例动作识别 Python* 演示十字路口摄像头 C++ 演示人姿估算 C++ 演示
Intel® Distribution of OpenVINO™ Toolkit 基准测试
详情请参见 安装面向 Linux* 的 Intel® OpenVINO™ 工具套件分发版。
对腾讯云CVM服务器有疑惑?想了解产品收费? 联系解决方案专家
腾讯云限时活动1折起,即将结束: 马上收藏
同尘科技为腾讯云授权服务中心,购买腾讯云享受折上折,更有现金返利:同意关联,立享优惠
阿里云解决方案也看看?: 点击对比阿里云的解决方案
本文来自投稿,不代表新手站长_郑州云淘科技有限公司立场,如若转载,请注明出处:http://www.cnzhanzhang.com/16961.html